Style Transfer with PyTorch
In this post, I would like to share my notes from the ‘Style Transfer’ lecture given by Udacity, Intro to Deep Learning with PyTorch. You may find the references below.
The key is using the technique that a trained CNN to separate the content from the style of an image. Then you can merge the content of one image and style of another and you will get a new image.
content image + style image = target image
Separating Style & Content
In deep networks, the image is transformed and the layers care about the content of the image, rather than texture and colors. But what about style? It is texture, colors, curvature…
VGG19 Paper Summary
In this paper[1] style transfer uses the features found in 19 layer VGG network.
- Input: a color image.
- Pass through conv and pool layers.
- Finally 3 FC layers. Classify the image.
- In btw 5 pooling layers –> 2 or 4 conv layers.
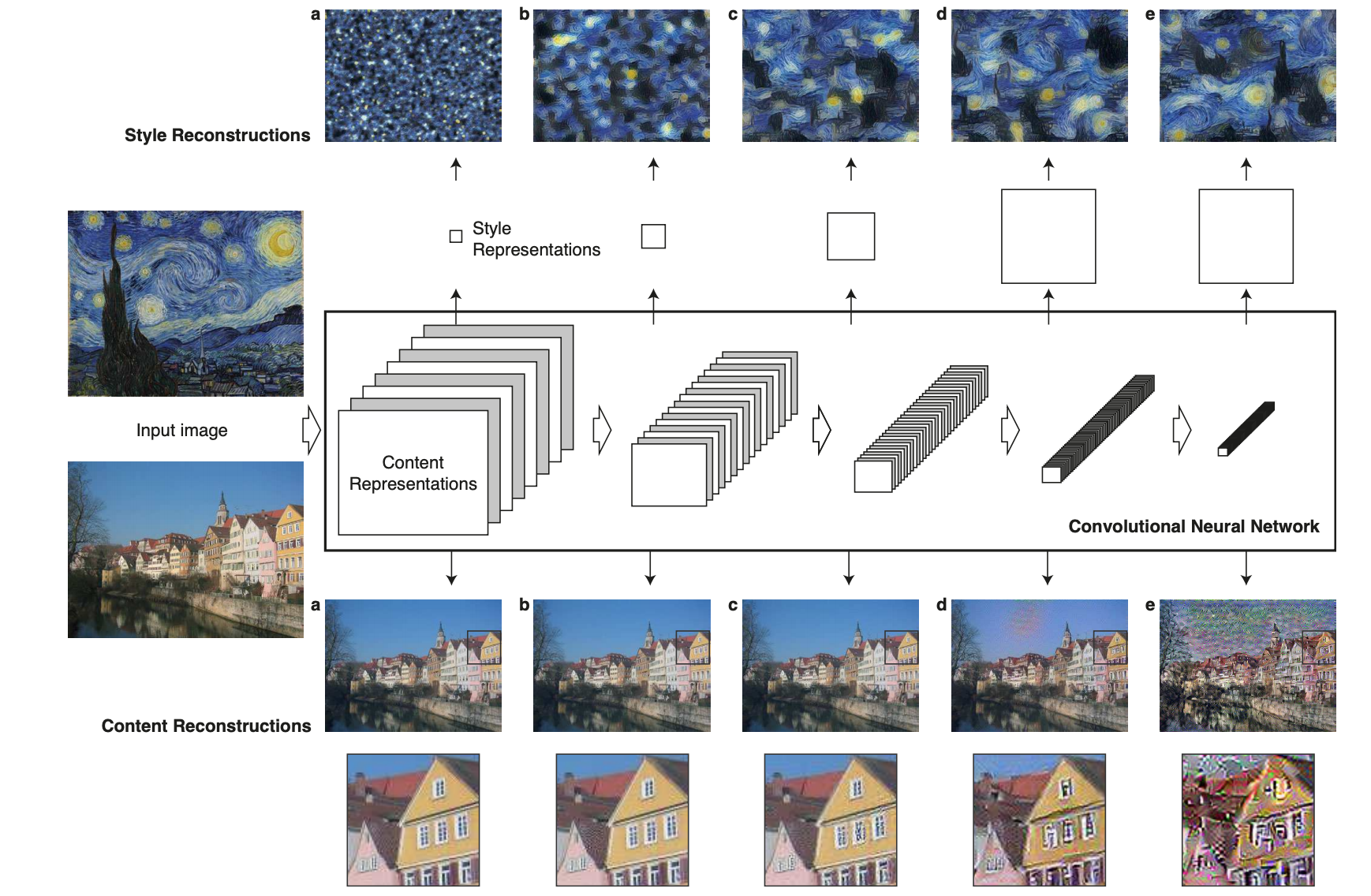
Explanation of the Figure:
This is an image representations in a Convolutional Neural Network (CNN).
A given input image is represented as a set of filtered images at each processing stage in the CNN. While the number of different filters increases along the processing hierarchy, the size of the filtered images is reduced by some down sampling mechanism (e.g. max-pooling) leading to a decrease in the total number of units per layer of the network.
Content Reconstructions:
We can visualise the information at different processing stages in the CNN by reconstructing the input image from only knowing the network’s responses in a particular layer.
We reconstruct the input image from from layers:
- ‘conv1 2’ (a),
- ‘conv2 2’ (b),
- ‘conv3 2’ (c),
- ‘conv4 2’ (d)
- ‘conv5 2’ (e) of the original VGG-Network.
We find that reconstruction from lower layers is almost perfect (a–c). In higher layers of the network, detailed pixel information is lost while the high-level content of the image is preserved (d,e).
Style Reconstructions
On top of the original CNN activations we use a feature space that captures the texture information of an input image. The style representation computes correlations between the different features in different layers of the CNN. We reconstruct the style of the input image from a style representation built on different subsets of CNN layers
- ‘conv1 1’ (a),
- ‘conv1 1’ and ‘conv2 1’ (b),
- ‘conv1 1’, ‘conv2 1’ and ‘conv3 1’ (c),
- ‘conv1 1’, ‘conv2 1’, ‘conv3 1’ and ‘conv4 1’ (d),
- ‘conv1 1’, ‘conv2 1’, ‘conv3 1’, ‘conv4 1’ and ‘conv5 1’ (e).
This creates images that match the style of a given image on an increasing scale while discarding information of the global arrangement of the scene.” [1]
Content
- Conv_Layer output is the content representation of the input.
- Next when it sees the style image it will extract features from multiple layers that represent the style of the image.
Target image can be started from blank canvas or copy of the content image. Target image’s content should be close to content image and its style should be close to the style image.
We need to compare content representation od content image and content representation of target image.
How?
Content Loss
Tc: target content rep, Cc: content content rep
CONTENT LOSS = 1/2 * Sum (Tc - Cc)^2
The only value that change is Tc. We are not training CNN, but we are using backpropagation to min the loss function.
Style
We need to calculate the difference btw target image and style image. We find the similarities btw features in multiple layers in the network.
- Include correlations btw multiple layers of different sizes
- we can obtain multiscale style representation of te input image.
Style representation calculation:
It is calculated by using all conv layers first channel: conv1_1, conv2_1 … The correlations at each layer are given by a GRAM MATRIX.
GRAM MATRIX
- Input image 4*4
- Use 8 filters for conv layer
- Output: 4*4 in height and weight and 8 in depth. –> It has 8 features maps that we want to find relationships between.
Operations:
- Vectorize the values in this layer: 8 * 4 * 4 -> 4*4=16 (one feature map):
8*16 - Take the transpose of this matrix :
8*16 - Multiply these two matrices:
8*8
Result of the gram matrix contains non localized information about the layer.
What is nonlocalized info??
It is information that would still be there even if an image was shuffled around in space. Even if the content of a filtered image is not identifable, you should be able to see the prominent colors and textures ie. the style!
Matrix(8 * 16) * Matrix(16 * 8) = Gram Matrix(8 * 8) –> its values indicates the similarities btw the layers.
- Ref: https://en.wikipedia.org/wiki/Gramian_matrix
An important application is to compute linear independence: a set of vectors are linearly independent if and only if the Gram determinant (the determinant of the Gram matrix) is non-zero.
- Ref: https://stackoverflow.com/questions/55546873/how-do-i-flatten-a-tensor-in-pytorch
How to reshape the tensor?
import torch
input = torch.rand(3, 8, 8)
print(input.shape) # torch.Size([3, 8, 8])
print(input.flatten(start_dim=1, end_dim=2).shape) # torch.Size([3, 64])
reshape_input = input.flatten(start_dim=1, end_dim=2)
reshape_input.shape # torch.Size([3, 64])
How to reshape the tensor? –> In the solution
# get the batch_size, depth, height, and width of the Tensor
_, d, h, w = tensor.size()
# reshape so we're multiplying the features for each channel
tensor = tensor.view(d, h * w)
# calculate the gram matrix
gram = torch.mm(tensor, tensor.t())
Style Loss
- Ss = Style image style
- Ts = Target image style
Loss = a * Sum(wi (Tsi - Ssi)^2 –> a is a constant that accounts for the number of values in each layer.
Loss
Total Loss =Loss_content + Loss_style
By using backpropagation we change the target image to minimize the loss.
Since these two losses can have very different values: (0.1 + 102) we need to treat them equally:
Total Loss = α * Loss_content + Β * Loss_style
Effect of Alpha & Beta Ratio:
- α / Β = 1/10 —> more content + less style (we can see the shape pf house clearly)
- α / Β = 1/10000 —> less content + more style (we loose the shape of house)
The more small α / Β ratio the more style you see!
Coding Tips
-
Load VGG features, not classification part
vgg = models.vgg19(pretrained=True).features -
Freeze all VGG parameters since we’re only optimizing the target image
for param in vgg.parameters(): param.requires_grad_(False) -
Features of Vgg19:
Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (17): ReLU(inplace=True) (18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (24): ReLU(inplace=True) (25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (26): ReLU(inplace=True) (27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (31): ReLU(inplace=True) (32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (33): ReLU(inplace=True) (34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (35): ReLU(inplace=True) (36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) -
Classifier of Vgg19:
Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=1000, bias=True) ) -
How to use cuda?
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") vgg.to(device) -
Load image with image path
image = Image.open(img_path).convert('RGB') -
Use tranformation to resize normalize and turn to tensor:
transforms.Compose([ transforms.Resize(size), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]) # discard the transparent, alpha channel (that's the :3) and add the batch dimension image = in_transform(image)[:3,:,:].unsqueeze(0) -
Load both style and content image. They may have different shapes. Use content image hegiht and weight for style image.
style = load_image(path, shape=content.shape[-2:]).to(device) -
Since we turn the image to tensor:
print(content) tensor([[[[-1.8953, -1.9467, -1.9295, ..., -0.1999, -0.1999, -0.3027], [-1.9980, -2.0152, -1.9467, ..., -0.4568, -0.3369, -0.1657], [-1.9809, -1.9809, -1.9295, ..., -0.8164, -0.5596, -0.3027], ..., -
If you want to see the image you should be turn it to numpy array, transpose, normalize it and clip the values, then use plt.imshow(image) to see the image.
image = tensor.to("cpu").clone().detach() image = image.numpy().squeeze() image = image.transpose(1,2,0) image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406)) image = image.clip(0, 1) -
Select the layers you would like to use: {‘0’: conv1_1, ‘3’: conv2_1 …}
-
Take the input image. pass through each layer, store the output of the layer. If this layer is one of out layers, store the output in features dictionary.
vgg._modules.items() odict_items([('0', Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('1', ReLU(inplace=True)), name, layer in vgg._modules.items(): name = '0' layer = Conv2d(3, 64, kernel_size=(3, 3) layers['0']= conv1_1 output = layer(input image) features = {layers['0']: [output..]} features = {'conv1_1': [output..]} -
You can calculate, target, content and style features.
-
Calculate gram matrix
# get the batch_size, depth, height, and width of the Tensor _, d, h, w = tensor.size() # reshape so we're multiplying the features for each channel tensor = tensor.view(d, h * w) # calculate the gram matrix gram = torch.mm(tensor, tensor.t()) -
Calculate the gram matrices for each layer of our style representation
-
Create target image by cloning the content image and it require gradient
target = content.clone().requires_grad_(True).to(device) -
Assign weights to selected style layers. Assign alpha and beta.
weighting earlier layers more will result in *larger* style artifacts -
Use optimizer = optim.Adam([target], lr=0.003)
-
Decide the number of iterations. It may be 2000 or 5000
-
content_loss = torch.mean((target_features[‘conv4_2’] - content_features[‘conv4_2’])**2)
-
For each layer in layers:
- get the features (output) of target and style
- calculate gram matrix
- layer_style_loss = style_weights[layer] * torch.mean((target_gram - style_gram)**2)
- style_loss += layer_style_loss / (d * h * w)
-
Total Loss: content_weight * content_loss + style_weight * style_loss
-
Optimization part:
optimizer.zero_grad() total_loss.backward() optimizer.step()
References
Key Words
- Pre-trained VGG19, Style Transfer, Gram Matrix, PyTorch, Style Transfer Loss